先说判断:Claude Opus 4.8 这次最值得看的,不是“又一个更强模型”,而是 Anthropic 开始把模型能力系统性推向 AI 工程与 Agent 执行层:更强的真实仓库编程、更低的任务偷懒率、更像工程系统的 Dynamic Workflows,以及更可控的推理成本结构。
如果只把 Claude Opus 4.8 看成 Opus 4.7 的一次常规升级,你会低估这次发布的意义。它更像一次能力重心的重新划分:从“回答得更好”,转向“在复杂工作流里做得更稳”。
对开发团队来说,这种变化尤其关键。因为企业真正缺的,往往不是一个会聊天的模型,而是一个能读仓库、拆任务、暴露风险、推动交付的执行系统。Claude Opus 4.8 正在向这个方向更近一步。

一、为什么这次发布值得单独拎出来看
距离 Opus 4.7 仅过去 43 天,Anthropic 却没有沿着“再抬一点基准分数”的传统路径走,而是明确瞄准企业与开发团队最痛的三个问题:复杂代码仓库改不动、长链路 Agent 任务不稳、模型在不确定时喜欢臆测。
这也是为什么 Opus 4.8 的价值不只是“能力更强”,而是它对“AI 什么时候能真正进入生产工作流”这个问题,给出了更具体的答案。它开始更像工程系统,而不是单轮问答接口。
二、这次更新最关键的五个信号
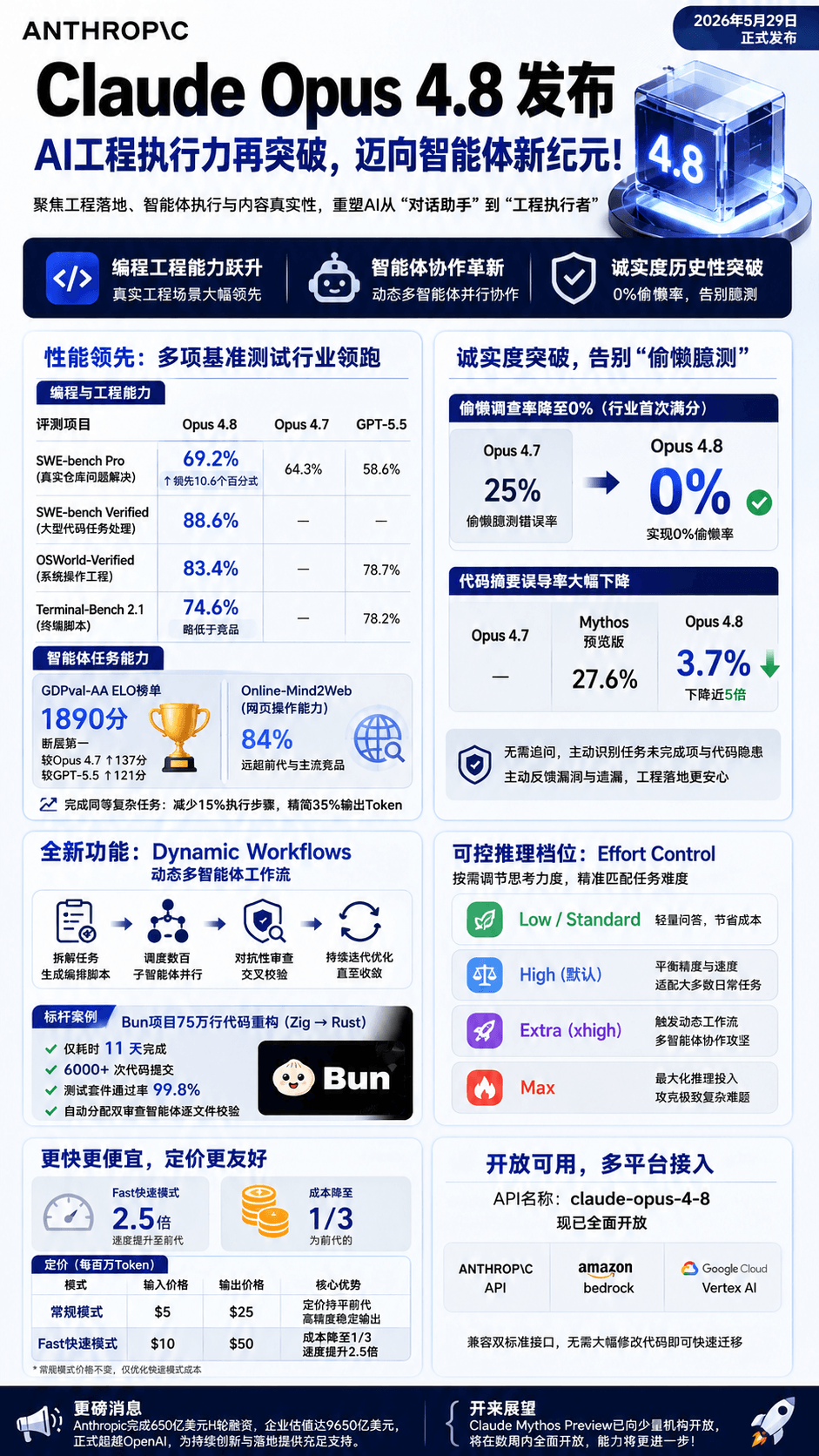
| 维度 | 关键信号 | 对团队意味着什么 |
|---|---|---|
| 真实工程编程 | SWE-bench Pro 69.2%,SWE-bench Verified 88.6%,OSWorld-Verified 83.4%。 | 对真实仓库、跨文件修改、系统级工程任务的处理更接近生产环境要求。 |
| 智能体执行 | GDPval-AA ELO 1890,同复杂任务下步骤减少 15%,输出 Token 减少 35%。 | 更少无效循环,更高完成率,长链路任务的单位成本和失败率都有望下降。 |
| 模型诚实度 | 反直觉代码追踪测试中偷懒率降至 0%,代码摘要误导率降至 3.7%。 | 模型更愿意暴露没做完的部分,这比“更会答题”更适合高风险工程场景。 |
| 工作流能力 | Dynamic Workflows 支持任务拆解、并行子智能体、对抗审查和断点续跑。 | Agent 不再只是一个窗口里的助手,而开始像可调度的多工位执行体系。 |
| 成本与速度 | Fast 模式速度提升到前代的 2.5 倍,常规模式定价维持不变。 | 团队可以把高精度模式和高频模式拆开使用,减少试错时的成本压力。 |
1. 编程能力:重点不只是补全,而是更接近“能交付”
从 Anthropic 披露的系统评测卡来看,Opus 4.8 最亮眼的部分是面向真实工程环境的编程能力。SWE-bench Pro 69.2% 的成绩,意味着它在面对真实仓库问题时,不只是能解释代码,还更可能把修改真正做对。
OSWorld-Verified 83.4% 的表现同样值得关注,因为它更接近系统操作和工程执行场景。也就是说,这一代模型的提升,不再局限在编辑器补全,而是在“看懂项目并推进任务”这件事上更进一步。
2. Agent 能力:步骤更少、输出更短,通常比单点跑分更重要
AI 智能体真正落地时,一个非常现实的问题是:它会不会走很多弯路。GDPval-AA ELO 冲到 1890 分,以及执行步骤减少 15%、输出 Token 减少 35%,说明 Opus 4.8 在面对真实工作流时,开始更少做无效动作。
这件事比单次回答更漂亮更有价值。因为一旦模型要跨越终端、网页、文件系统和测试链路,稳定推进比局部聪明重要得多。
不要误读:Claude Opus 4.8 并不意味着在所有细分基准上都没有短板。以 Terminal-Bench 2.1 为例,它虽然显著提升,但仍略低于部分竞品。不过对要把 AI 接进真实工程链路的团队来说,“稳定完成”往往比“某一项第一”更重要。
3. 诚实度:0% 偷懒率,比“更聪明”更稀缺
很多团队迟迟不愿把大模型深度接进工程流程,核心顾虑不是它不够聪明,而是它会不会在不确定时装作完成了任务。Opus 4.8 在反直觉代码追踪测试里把偷懒率压到 0%,这比单纯提高基准分数更能打动企业用户。
代码摘要误导率降到 3.7% 也说明同一个趋势:模型更愿意承认遗漏、更主动暴露风险。对于代码审查、回归修复、批量改造这类高成本场景,这种“更老实”往往直接决定能不能上线使用。
三、Dynamic Workflows:Agent 从单兵作战走向工程编排
这次升级里最有行业象征意义的能力,是 Dynamic Workflows。它不再把 Agent 理解为一个单线程对话体,而是把复杂任务拆解成多个可并行、可审查、可回放的执行单元。
- 先拆分任务,生成面向当前工程的编排脚本。
- 再把任务分发给数十到数百个子智能体并行推进。
- 同时引入对抗性审查智能体,专门寻找漏洞、遗漏和冲突。
- 最后保留过程状态,支持长周期任务断点续跑与持续迭代。
这意味着 Agent 的价值判断标准会变。下一阶段大家比的,不只是模型单次响应质量,而是谁更像一个可调度的工程系统,谁能在数小时到数天的任务链路里保持一致性。
Anthropic 给出的 Bun 项目案例也很有代表性:一个 75 万行代码的语言迁移项目,在 11 天内完成了 6000 多次提交,最终测试通过率达到 99.8%。无论你是否把它看成极端案例,它至少说明了这家公司正在把“多智能体工程化作业”当成主航道来推。
四、Effort Control:把精度、速度和成本放回同一套拨盘
另一项很实用的更新是 Effort Control,也就是把模型推理力度做成多档可调。对普通用户来说,这也许只是“可以更快”或“可以更认真”;但对团队使用者来说,它其实在重构成本模型。
- 轻量档适合快速问答、文档整理、简单改写,优先控制 Token 成本。
- 高强度档适合复杂代码定位、跨模块改造、测试补齐和长链路任务。
- 更高档位还可以和 Dynamic Workflows 配合,把推理预算换成更稳定的交付过程。
当模型推理强度可以按任务场景动态切换,团队就不需要拿同一种配置处理所有工作。这比单纯讨论“模型贵不贵”,更贴近真实生产环境。
五、谁应该优先关注 Claude Opus 4.8
- 正在用 Claude Code 或其他终端 Agent 推进真实仓库任务的开发团队。
- 需要处理多文件重构、测试补齐、脚本串联和网页自动化的工程师。
- 对审计、可追责、失败显式暴露更敏感的企业研发场景。
- 已经部署 Anthropic API、Amazon Bedrock 或 Google Cloud Vertex AI 的现有用户。
如果你的主要需求只是低成本的日常问答、轻量写作或者简单摘要,这次升级的优势未必能完全释放出来。但如果你的目标是让 AI 真正推进工程任务,它的意义就会明显得多。
六、对行业意味着什么
过去一年,大模型竞争常常被简化成“谁更强、谁更会写、谁榜单更高”。但 Claude Opus 4.8 释放出的信号是,下一阶段的核心变量已经变了:谁更像一个能接入团队流程、能被拆解调度、能在关键节点主动暴露风险的工程系统。
这也是 Anthropic 与 OpenAI 等厂商竞争方式的一个微妙分野。前者这次强调的是工程落地、诚实度和工作流编排的一体化;后者则更早把 AI 编程和 Agent 产品化推向大众。两条路线正在同一个终点会合:AI 不再只是对话助手,而是在成为软件团队里的新执行层。
目前 Opus 4.8 已以 claude-opus-4-8 的模型名称开放,可通过 Anthropic 官方 API、Amazon Bedrock 和 Google Cloud Vertex AI 接入。对已经在 Anthropic 生态里的团队来说,迁移与试用门槛并不高。
七、结语:这不是一次普通版本号更新
真正值得关注 Claude Opus 4.8 的原因,不是它又在多少榜单上赢了一次,而是它更清晰地展示了 AI 工程下一步会怎么走:更强调真实仓库能力、更强调多智能体协作、更强调失败显式暴露,也更强调把精度和成本一起纳入工作流控制。
如果说上一阶段的关键词是“让 AI 会写代码”,那么这一阶段的关键词更像是“让 AI 能把复杂任务稳定做完”。从这个角度看,Claude Opus 4.8 的发布,确实称得上是 AI 工程与智能体的一次新范式信号。
